Data Structures and Algorithms using Python
|
Copyright © 2023
by Rance Necaise |
2.4 IteratorsTraversals are very common operations, especially on containers. A traversal iterates over the entire collection, providing access to each individual element. Traversals can be used for a number of operations, including searching for a specific item or printing an entire collection. Python's container types---strings, tuples, lists, and dictionaries---can be traversed using the Not all abstract data types should provide a traversal operation, but it is appropriate for most container types. Thus, we need a way to allow generic traversals to be performed. One way would be to provide the user with access to the underlying data structure used to implement the ADT. But this would violate the abstraction principle and defeat the purpose of defining new abstract data types. Python, like many of today's object-oriented languages, provides a built-in iterator construct that can be used to perform traversals on user-defined AD Ts. An iterator is an object that provides a mechanism for performing generic traversals through a container without having to expose the underlying implementation. Iterators are used with Python's # Iterate over the bag and check the ages. for time in bag : if time >= startTime and time <= endTime : numValid = numValid + 1 Designing an IteratorTo use Python's traversal mechanism with our own abstract data types, we must define an iterator class, which is a class in Python containing two special methods, The constructor defines two data fields. One is an alias to the list used to store the items in the bag, and the other is a loop index variable that will be used to iterate over that list. The loop variable is initialized to zero in order to start from the beginning of the list. class BagIterator : def __init__(self, theList) : self._bagItems = theList self._curItem = 0 The def __iter__(self) : return self The def __next__(self) : if self._curItem < len(self._bagItems) : item = self._bagItems[ self._curItem ] self._curItem += 1 return item else : raise StopIteration The method first saves a reference to the current item indicated by the loop variable. The loop variable is then incremented by one to prepare it for the next invocation of the Finally, we must add an def __iter__(self) : return BagIterator(self._theItems) This method, which is responsible for creating and returning an instance of the The complete implementation of the Program Listing
Using IteratorsWith the definition of the for item in bag : print(item) is executed, Python automatically calls the 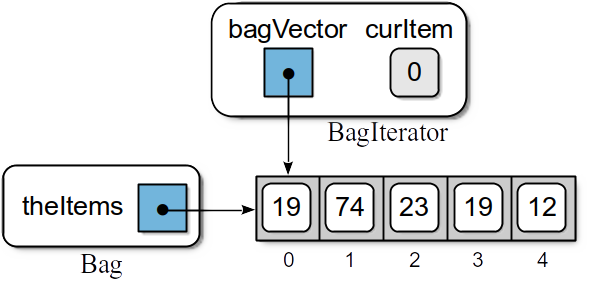
Figure 2.4.1: The
Bag and BagIterator objects before the first loop iteration.The The following code segment illustrates how Python actually performs the iteration when a # Create a BagIterator object for myBag. iterator = iter(myBag) # Repeat the while loop until break is called. while True : try: # Get the next item from the bag. If there are no # more items, the StopIteration exception is raised. item = next(iterator) # Perform the body of the for loop. print(item) # Catch the exception and break from the loop when we are done. except StopIteration: break
|