Data Structures and Algorithms using Python
|
Copyright © 2023
by Rance Necaise |
5.2 Big-O NotationInstead of counting the precise number of operations or steps, computer scientists are more interested in classifying an algorithm based on the order of magnitude as applied to execution time or space requirements. This classification approximates the actual number of required steps for execution or the actual storage requirements in terms of variable-sized data sets. The term big-O, which is derived from the expression "on the order of," is used to specify an algorithm's classification. Defining Big-OAssume we have a function that represents the approximate number of steps required by an algorithm for an input of size . For the second version of our algorithm in the previous section, this would be written as 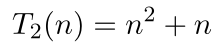
Now, suppose there exists a function defined for the integers , such that for some constant , and some constant , 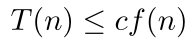
for all sufficiently large values of . Then, such an algorithm is said to have a time-complexity of, or executes on the order of, relative to the number of operations it requires. In other words, there is a positive integer and a constant (constant of proportionality) such that for all , . The function indicates the rate of growth at which the run time of an algorithm increases as the input size, , increases. To specify the time-complexity of an algorithm, which runs on the order of , we use the notation 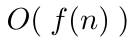
Consider the two versions of our algorithm from earlier. For version one, the time was computed to be . If we let , then 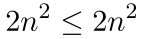
for a result of . For version two, we computed a time of . Again, if we let , then 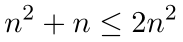
for a result of . In this case, the choice of comes from the observation that when , we have and , which satisfies the equation in the definition of big-O. The function is not the only choice for satisfying the condition . We could have said the algorithms had a run time of or since and when . The objective, however, is to find a function that provides the tightest (lowest) upper bound or limit for the run time of an algorithm. The big-O notation is intended to indicate an algorithm's efficiency for large values of . There is usually little difference in the execution times of algorithms when is small. Constant of ProportionalityThe constant of proportionality is only crucial when two algorithms have the same . It usually makes no difference when comparing algorithms whose growth rates are of different magnitudes. Suppose we have two algorithms, and , with run times equal to and respectively. has a time-complexity of with and has a time of with . Even though has a smaller constant of proportionality, is still slower and, in fact an order of magnitude slower for large values of . Thus, dominates the expression and the run time performance of the algorithm. The differences between the run times of these two algorithms is shown numerically in Table 5.2.1 and graphically in Figure 5.2.1.
Table 5.2.1: Graphical comparison of the data from Figure 5.1.2
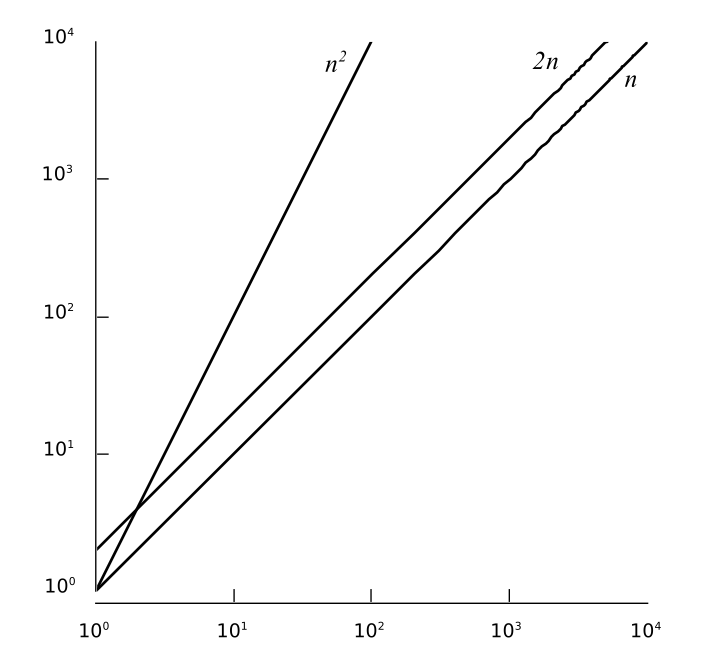
Figure 5.2.1: Graphical comparison of the data from Table 5.1.2
Constructing T(n)Instead of counting the number of logical comparisons or arithmetic operations, we evaluate an algorithm by considering every operation. For simplicity, we assume that each basic operation or statement, at the abstract level, takes the same amount of time and, thus, each is assumed to cost constant time. The total number of operations required by an algorithm can be computed as a sum of the times required to perform each step: 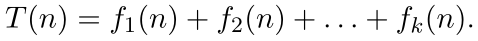
The steps requiring constant time are generally omitted since they eventually become part of the constant of proportionality. Consider Figure 5.2.2 (a), which shows a markup of version one of the algorithm from earlier. The basic operations are marked with a constant time while the loops are marked with the appropriate total number of iterations. Figure 5.2.2 (b) shows the same algorithm but with the constant steps omitted since these operations are independent of the data set size. 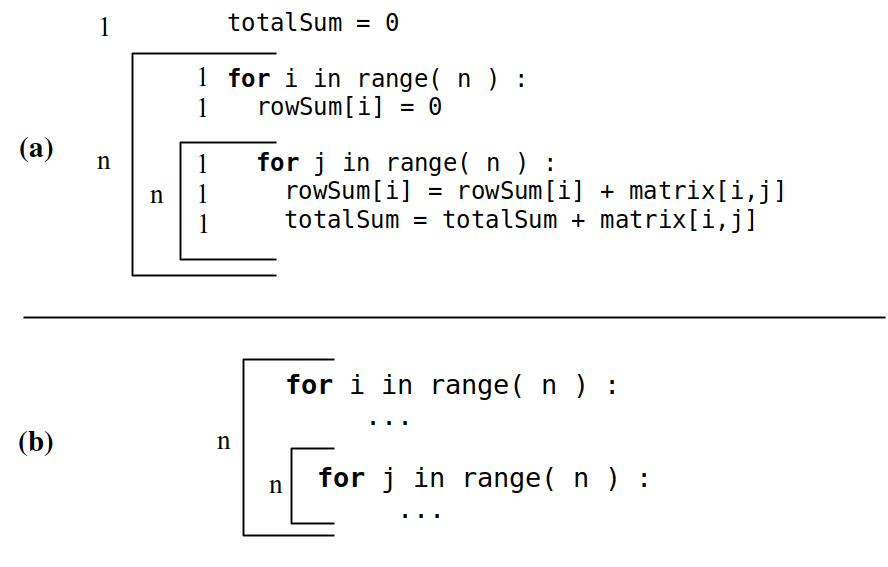
Figure 5.2.2: Markup for version one of the matrix summing algorithm: (a) all operations are shown, and (b) only the non-constant time steps are shown.
Choosing the FunctionThe function used to categorize a particular algorithm is chosen to be the dominant term within . That is, the term that is so large for big values of , that we can ignore the other terms when computing a big-O value. For example, in the expression 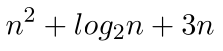
the term dominates the other terms since for , we have 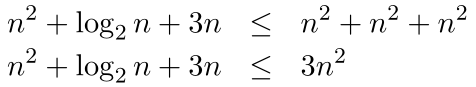
which leads to a time-complexity of . Now, consider the function and assume it is the polynomial that represents the exact number of instructions required to execute some algorithm. For small values of (less than 16), the constant value dominates the function, but what happens as gets larger, say ? The term becomes the dominant term, with the other two becoming less significant in computing the final result. Classes of AlgorithmsWe will work with many different algorithms in this text, but most will have a time-complexity selected from among a common set of functions, which are listed in Table 5.2.2 and illustrated graphically in Figure 5.2.3. Algorithms can be classified based on their big-O function. The various classes are commonly named based upon the dominant term. A logarithmic algorithm is any algorithm whose time-complexity is . These algorithms are generally very efficient since will increase more slowly than . For many problems encountered in computer science will typically equal 2 and thus we use the notation to to imply . Logarithms of other bases will be explicitly stated. Polynomial algorithms with an efficiency expressed as a polynomial of the form 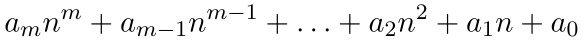
are characterized by a time-complexity of since the dominant term is the highest power of . The most common polynomial algorithms are linear (), quadratic (), and cubic (). An algorithm whose efficiency is characterized by a dominant term in the form is called exponential. Exponential algorithms are among the worst algorithms in terms of time-complexity.
Table 5.2.2: Common big-O functions listed from smallest to largest order of magnitude.
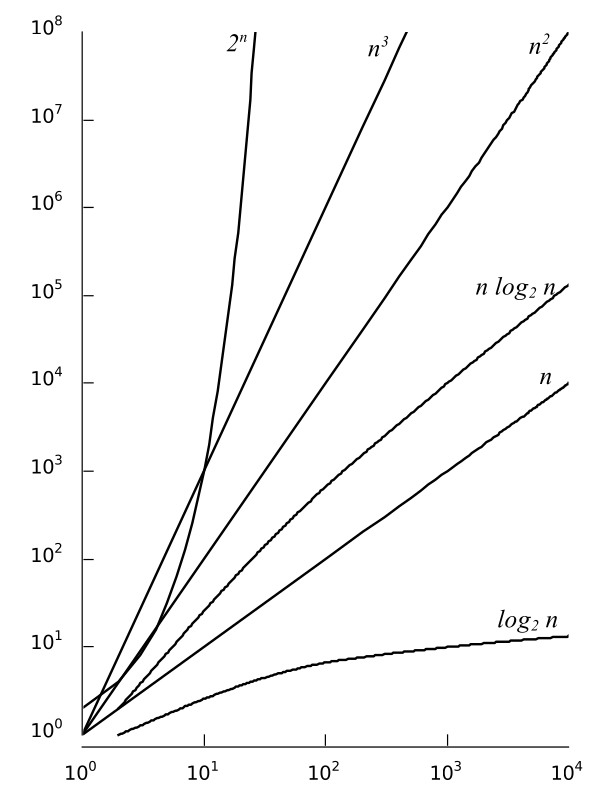
Figure 5.2.3: Growth rates of the common time-complexity functions.
|